
Screenscrape av Øya-programmet
Forskningsprosjektet Sky & Scene, hvor jeg jobber, ser blant mye annet nærmere på strømmetallene fra WiMP før, under og etter Øya-festivalen. For å gjøre dette trenger vi en liste over hvilke artister som spiller, hvilken dag de spiller og når på dagen de spiller. Før dataene kan analyseres må disse dataene være tilgjengelige i Excel-ark og i CSV-format og i databasen hvor strømmetallene finnes. Dataene må hentes og struktureres i et bestemt format.
Et godt utgangspunkt er å samle dataene i et CSV-format. CSV står for Comma separated values, kommaseparerte verdier, og er en liste hvor verdiene er for en forekomst er samlet på en linje, og hvor forekomstens data-attributter, også kalt variabler, er separert med – you guessed it – komma. Et lignende format kan du finne i Excel hvor èn forekomst finnes på èn linje, og denne forekomstens variabler oppgis i kolonner.
Finne dataene
Ok, nok om formatering. Hvor kan vi finne dataene? Et naturlig utgangspunkt er festivalens hjemmesider. På oyafestivalen.com (den engelske hjemmesiden til festivalen) finner vi et menyvalg kalt “program“, og her finner vi også programmet.
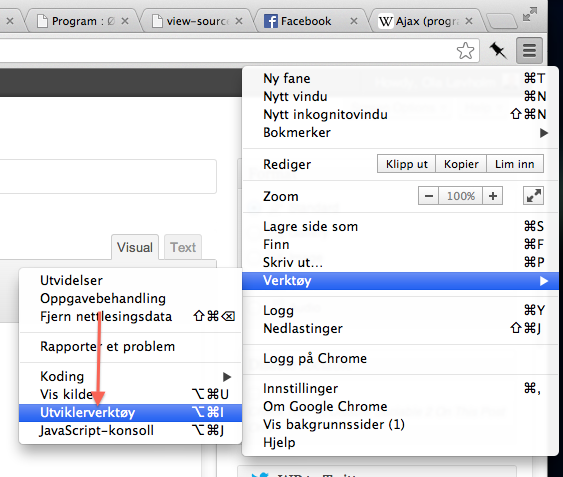
For å screen scrape programmet hjelper det lite med den visuelle presentasjonen av siden og vi må derfor se på HTML kilden. I Google Chrome finner du denne ved å høyreklikke i web-vinduet for så å klikke på “vis sidekilde”, her kan vi finne HTML-koden. Eventuelt kan du kopiere denne lenken inn i din Chrome browser: “view-source:http://oyafestivalen.com/program/#all“
Dersom du gikk inn i kildekoden vil du se at listen med artister mangler. Hvorfor? Jo, fordi listen er ganske lang og benyttes av flere kilder lastes ikke listen med programmet inn av selve program-siden. Den lastes inn asynkront med AJAX (Asynchronous Javascript and XML). Finn fram Chrome Developer Tools som finnes i menyen, og gå til Network fanen. Last siden igjen ved å klikke på sirkelen med pil til venstre for URL-feltet.
Her kan du se at en fil kalt getArtist.php er lastet (bilde 1), og at denne filen ikke lastes som en del av originalforespørselen vår til web-tjeneren, men istedet er lastet inn via Javascript. Dersom vi klikker for å se på hva denne URL-en leverer kan vi se at artistlisten kommer herifra. URLen til siden kan du finne ved å høyreklikke på navnet getArtist.php og så velge “copy link address”.
Når du har URLen (http://oyafestivalen.com/wp-content/themes/oya13_new/includes/ajax/program/getArtists.php) kan du kopiere denne inn i nettleser vinduet ditt. Du skal nå få en liste uten spesiell formatering som ser omtrent slik ut:

OK, nå har vi funnet dataene vi trenger. Nå må vi bare finne en god måte å hente de ut fra siden. La oss ta en titt på kilden bak konsertlista. Her finner vi både dataene og strukturen vi trenger:

Her kan vi se at:
- Ytterst har vi en div-tag med klassen “table title”. Denne innleder forklaringen som står over kolonnen i visningen.
- Vi har en uordnet liste (ul-tag) med klassen “table”
- Den uordnede listen har flere barn som er satt i liste elementer (li). Disse benytter seg av HTML5 data-attributter, men disse skal vi ikke bruke i denne omgang.
- Hvert liste-element har et span element med klassen “name”, hvor innholdet er navnet på artisten
- Liste-elementet har også en klasse “scene” med scene navnet som innhold.
- Sist har liste-elementet også en “date” klasse med de tre første bokstavene på dagen, tre non breaking spaces (HTML syntaks: ) og tidspunkt for konsert-start.
Her finner vi alle dataene, og formateringen er også lik for alle elementene i lista med klassen “table”.
Når vi nå har funnet datakilden kan vi begynne å trekke ut dataene for videre bruk.
Screen scrape med Ruby og Nokogiri
Vi har nå funnet kilden og da kan vi benytte oss av Ruby og biblioteket (ruby-term: gem) Nokogiri.
Før vi begynner å hente dataene må vi gjøre klart scriptet som skal hente dataene fra festivalens hjemmeside. Vi inkluderer nokogiri som skal hjelpe oss å parsere datakilden. Samtidig laster vi også inn csv-bibliotek for å skrive ut filene og open-uri for å kunne lese URI-kilden som en fil.
#!/usr/bin/ruby # -*- encoding : utf-8 -*- require 'nokogiri' require 'open-uri' require 'csv'
Konsert klassen
For å lagre og manipulere dataene lager vi en klasse for å lagre de fire verdiene vi trenger: artist, scene, date og datetime. Hos kilden finner vi de tre første verdiene og datetime konstruerer vi utfra date.
For klassen setter vi alle variablene vi skal benytte med en attr_accessor. Dette gjør at ruby selv genererer get og set-metoder for alle variablene listet etter funksjonen, noe som gjør at vi fritt kan hente og sette variablene fra instansene av klassen.
Vi skriver en initialize-metode, en konstruktør, som kalles når instansen opprettes. Siden vi allerede henter artist, scene og dato fra datakilden kaller vi konstruktøren med disse variablene slik at disse settes. For å oversette date til datetime, lager vi en dictionary med dagene og tilsvarende ISO-datoformat.
Legg merke til at når instans-variabelen @date settes, så gjøres det en del formatering. Fra kilden får vi datoformatet noe annerledes, så vi fjerner non-braking space, og bytter ut punktum med semikolon og sørger for at det er mellomrom mellom de tre bokstavene som angir dagen, og klokkeslettet. Når dette er gjort kaller vi en metode for å generere datetime-verdien basert på date-verdien. Vi bruker @ foran variabelnavnet for å markere at dette er en instanse-variabel.
metoden add_datetime gjør et oppslag i date_dict og bytter ut dag-bokstavene med ISO-dato, deretter henter den ut tidspunktet fra @date variabelen og interpolerer disse to verdiene til en datetime string.
Den siste metoden vi lager to_arr tar alle instanse-variablene og returnerer disse som en array. Siden CSV-funksjonen vi inkluderte tidligere kan lage en CSV-linje fra en array er dette en hendig måte å hente ut verdiene fra objektet.
class Concert
attr_accessor :artist, :scene, :date, :datetime
def initialize(artist, scene, date)
@date_dict = {'wed' => '2013-08-07' ,'thu' => '2013-08-08' ,'fri' => '2013-08-09' ,'sat' => '2013-08-10'}
@artist = artist.strip
@scene = scene.strip
@date = date.gsub(/\u00a0/, '').gsub('.',':').gsub(/([a-zA-Z]{3})(.)/,'\1 \2').strip
self.add_datetime
end
def to_arr
return [self.artist, self.scene, self.date, self.datetime]
end
def add_datetime
@datetime = "#{@date_dict[@date[0,3].downcase]} #{@date[4..9]}"
end
end
Lese dokumentet, hente ut dataene og lage objektene
Når vi nå har en datastruktur hvor vi kan lagre informasjonen, kan vi begynne å hente informasjonen fra internett. Aller først lager vi igjen en tom dictionary hvor vi ønsker å lagre våre konsert-objekter etterhvert som vi lager disse.
Vi bruker Nokogiris HTML klasse og lagrer denne til doc variabelen. Til denne sender vi en tekst-strøm som hentes fra URLen. Vi sender altså samme tekst som vi fikk fra getArtist.php kildekoden til Nokogiri.
Nokogiri har en utmerket methode kalt css. Denne metoden tar en CSS (Cascading Style Sheet) selektor og finner riktig element fra DOMen (Document Object Model) som Nokogiri holder. Vi ønsker å iterere over alle “.table li”-nodene (alle li-nodene under table-klassen), og gjør dette ved enkelt med .each metoden.
For hver “.table li” vi itererer over, henter vi ut innholdet av elementene som har klassene .name, .scene og .date og oppretter et objekt av Concert-klassen. Det siste vi gjør for hver iterasjon er å lagre objektet med artisten som nøkkel i vår concerts dictionary.
concerts = {}
doc = Nokogiri::HTML(open('http://oyafestivalen.com/wp-content/themes/oya13_new/includes/ajax/program/getArtists.php'))
doc.css('.table li').each do |el|
a = Concert.new(el.css('.name a').first.content,
el.css('.scene').first.content,
el.css('.date').first.content)
concerts[a.artist] = a
end
Printe objektene som CSV
Når vi har opprettet alle objektene ønsker vi å skrive ut alle variablene i disse til fil. Vi gjør dette ved å åpne en fil kalt output.csv med skrivetilgang. Deretter itererer vi igjennom alle objektene og bruker nøkkelen fra k-variabelen til å hente ut hvert enkelt objekt som finnes i vår concerts dictionary. For å kun få Øya-festivalens konserter (ikke klubb-Øya) sjekker vi at konserten fant sted på enten scenene “Enga”, “Klubben”, “Sjøsiden” eller “Vika” (Sjøsiden har feil format her som vi senere korrigerer i Excel). For hvert objekt hvis scene er inkludert blant Øya-scenene skrives det en linje til csv-fila som tar en array med verdier. Denne arrayen hentes fra to_arr metoden vi skrev i Concert-klassen.
CSV.open("output.csv", "wb") do |csv|
concerts.each do |k,v|
csv << concerts[k].to_arr if ['Enga','Klubben','Sjøsiden','Vika'].include? concerts[k].scene
end
end
Sånn. Nå burde du ha en CSV med alle Øya-artistene som du kan enten importere til en database eller åpne i Excel.
Hele scriptet:
#!/usr/bin/ruby
# -*- encoding : utf-8 -*-
require 'nokogiri'
require 'open-uri'
require 'csv'
require 'open-uri'
class Concert
attr_accessor :artist, :scene, :date, :datetime
def initialize(artist, scene, date)
@date_dict = {'wed' => '2013-08-07' ,'thu' => '2013-08-08' ,'fri' => '2013-08-09' ,'sat' => '2013-08-10'}
@artist = artist.strip
@scene = scene.strip
@date = date.gsub(/\u00a0/, '').gsub('.',':').gsub(/([a-zA-Z]{3})(.)/,'\1 \2').strip
self.add_datetime
end
def to_arr
return [self.artist, self.scene, self.date, self.datetime]
end
def add_datetime
@datetime = "#{@date_dict[@date[0,3].downcase]} #{@date[4..9]}"
end
end
concerts = {}
doc = Nokogiri::HTML(open('http://oyafestivalen.com/wp-content/themes/oya13_new/includes/ajax/program/getArtists.php'))
doc.css('.table li').each do |el|
a = Concert.new(el.css('.name a').first.content,
el.css('.scene').first.content,
el.css('.date').first.content)
concerts[a.artist] = a
end
CSV.open("output.csv", "wb") do |csv|
concerts.each do |k,v|
csv << concerts[k].to_arr if ['Enga','Klubben','Sjøsiden','Vika'].include? concerts[k].scene
end
end